
This post is a summary of the talk Natzir Turrado and myself did at Congreso Web in Zaragoza (Spain) and at the Lisbon SEO meetup (Portugal) (get the slides here), where we try to explain this technology and how SEOs and developers have to deal with it in order to make it accessible to search engines. We based this talk on our experience with clients that use Javascript Frameworks like Angular or React, friends or colleagues that have shared the data with us and on experiments we did in order to understand how search engines behave with Javascript. These are the points we are going to talk about:
- What is a PWA and how it works
- How search engines deal with Javascript (JS)
- Rendering approaches for JS sites
- Good practices for PWA and JS sites
- Experiment: PWA without prerender (CSR)
- Conclusion
Nowadays there are different solutions to solve mobile users’ needs. For example, at elmundo.es, if they want to offer a satisfactory experience to all the users that consume their news articles, they need to make sure that they serve each page currently in different ecosystems: mobile version and desktop version (with Dynamic Serving), APP (offline and more fluid navigation, and push notifications), AMP (as a requirement to appear on the Top Stories carrousel) and Facebook Instant Articles (Facebook’s AMP approach).
As you can see, those are a lot of ecosystems to be supported aside from the main website, and this is expensive and not very scalable for business.
If we talk about native APPs, these are the most common cons:
- They are normally more expensive than a normal website or web app. The price can vary from 25.000€ to 600.000€, being 150.000€ on average
- APP developers are scarce and highly demanded by startups, being offered very good salaries. In Barcelona, if you want to hire an APP developer, s/he probably is also on the recruitment process of Wallapop, Glovo, CornerJob or any other hot startup, and maybe you cannot compete with that.
- In a native APP, each step of the funnel costs you 20% of the users
- It’s another channel in which you will have to invest (aside from your normal website)
Another type of solution that exists nowadays, to solve more complex needs and heavier interactions on mobile, are the Mobile Web Apps (on a m. subdomain for example). These ones have some cons too:
- They do not allow offline navigation
- They are not indexable on APP stores.
- It’s more difficult to implement Responsive Web Design (RWD) with them
- It’s an extra technology you would need to develop and maintain for different browsers and devices.
Fortunately, nowadays there is a new development solution, initiated by Google, that has the best of both worlds, the Progressive Web Apps (PWA)
Tabla de contenidos
What is a PWA and how it works
A PWA is a web page that works for all users and all devices, but with the fluid experience of a native APP. This is a great advantage for websites with complex interactions. For example, if you navigate in your smartphone’s browser to Twitter and Instagram you will access their PWAs. There is no reason to use their native APPs, that consume lots of resources on the background, when you can just use their PWAs, install them on your home screen and be able to access Twitter and Instagram with most of their functionalities. Besides, it seems that Twitter is thinking about no longer maintaining their APP, as well as Starbucks. We suppose they will wait to get more users to add their PWA to their homescreen and to keep up the good numbers.
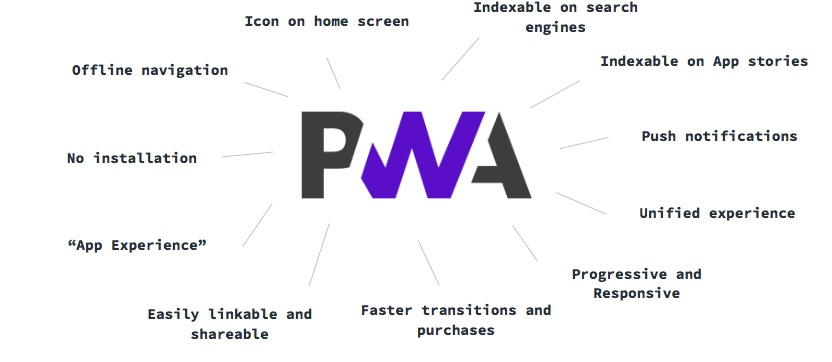
Some of the advantages of Progressive Web APPs are:
- They are APPs that can be indexed on search engines (bye bye APP indexing).
- They can also be indexed on APP stores
- They allow one-click purchases with the payment request api. This is one of the greatest advantages, taking into account that the abandon rate for card payments on mobile is 80%
- They allow push notifications
- They are progressive and responsive
- Easily shareable and likable (each content has its own URLs, same as on any website)
- Users do not need to install them on their smartphones
- We will see them on desktop soon (you can already “install” them on Chrome Os since almost one year ago)
- You can use them offline
- They enable faster transitions

We are not saying that PWAs are better than native APPs, but their advantages will probably influence developers into not choosing to develop a native APP.
PWA can have a First Contentful Pain faster than a normal website and faster and more fluid next interactions, like a native APP. It’s an important feature as load speed is the UX element that 75% of users care more about, according to this Google study. It seems that slow websites can be more stressful than watching an horror movie (according to this study from Ericsson ConsumerLab) and this means that you can lose up to 53% of your users if your mobile website takes more than 3 seconds to load, according to this other study from Google and SOASTA
Progressive Web Apps are developed using Javascript frameworks and libraries, which are becoming a standard as they make it easier for developers. This approach have the following advantages:
- It’s easier for developers to jump in PWA. They are modular, clean and facilitate core code reusability. Also, there is a big and collaborative community behind.
- Better performance and speed (for servers especially when using Client Side Rendering as we will see later).
- Cheaper, as they are open source and it’s easier to find developers. The are new and better frameworks appearing all the time (Vue JS for example is much easier to learn than React JS, one of the reasons why it’s overcoming it)
- They are a safer bet because of the big community and the big players involved (Google is behind Angular and Facebook is behind React JS)
For all these reasons, PWA are here to stay, so both SEOs and search engines need to deal with it, as their growth is unstoppable.
According to the Stack Overflow’s “2017 Developer Survey” (which 64000 developers answered), JavaScript is the most popular programming language and Node JS, Angular and React JS are in the top 5 most popular development technologies.
How Progressive Web Apps work
A PWA is a SPA/MPA (Single Page Application or Mutiple Page Application) which has two extra functionalities that makes it work: the service worker and the manifest
The service worker is the magic of PWA: it allows background synchronization, offline navigation and push notifications.
It works as a controller and in the middle of the client (the browser) and the server. It tells the browser cache to store files that have been already downloaded so, later on, the user is able to access the pages without downloading them again (that’s why it’s possible to navigate offline)
The manifest is a small JSON file included on the head of the HTML document. Among other things, the main functionality of this file is to allow a PWA to be installed in the home screen of the user’s smartphone so it can be used as an APP
With Microsoft’s PWA Builder you can easily create both a manifest and a service worker for your website. If you want to learn more about how to create a PWA, Google has a very useful tutorial
Nowadays all major browsers support PWA, but not all browsers support all the functionalities of PWA. Fortunately, this is changing fast as you can check on the “Can I use” website


How search engines deal with Javascript nowadays
Nowadays only Google and ASK render Javascript in a “decent” way. Baidu announced that they also do it, but after doing some tests, it seems that they don’t do it as well as Google or ASK. So, if your business is in USA, Russia or China, you cannot depend on Bing, Yahoo, Yandex or Baidu to render your JS website and you will have to make sure your content and links are working without JS.
Crawling != Rendering != Indexing != Ranking
When we talk about the abilities of a Search Engine to render JS, this kind of tests you see here are usually made. For example, doing a “site:” for a site that depends on JS to be visualised and crawled:
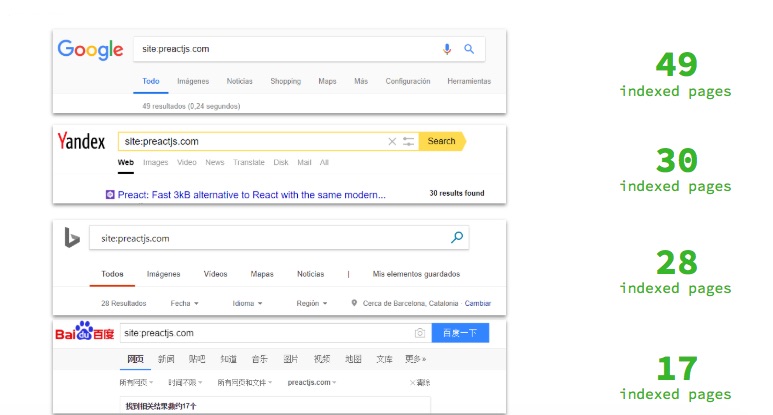

As you can see, the number of indexed pages varies in each of these search engines, but besides that, the fact that a search engine has a given number of URLs indexed doesn’t mean that they discovered them after rendering the page, nor that it is able to see 100% of what is in them (there may be external links pointing to different URLs of that site and the search engine just discover those URLs there, without being able to see what’s in them)
So if for example you try to search for some of the exact text strings of a JS site in different search engines, you will see that in some cases Google is the only one able to see and index that content.
Rendering a JS site costs a lot
So, if PWA are a trendy thing right now, and lots of websites are using JS, why not all search engines are already rendering JS? It’s simple: because it costs a lot (both resources and money)
According to a study made with the top 500 sites on archive.org, 50% of the websites take an average of 14s in allowing the user to interact on mobile, which is too much time.
Here it’s important to understand that a JS file of 170KB is not the same as an image of 170KB: although the browser will spend more or less the same time downloading both files, the image will be rendered and visible to the user very fast (in milliseconds), while the JS has to be parsed, compiled and executed by the browser, consuming more resources and time.
To get an idea of how much does it cost to render JS for a crawler, we have the numbers ahrefs shared. Each 24h:
- They crawl 6 billion pages
- They render 30 million pages
- For that, they use 400 servers.
If you do some maths, for each page they render, they crawl 200 pages. According to themselves, if they decide to crawl and render all the URLs they have on their index with this same pace, they estimate they would need between 10.000 and 15.000 extra servers (between 20 and 30 times more servers), so you can imagine the amount of money that would be (machines, electricity, maintenance…)
Google won’t wait indefinitely to render a page
Because of the high cost of rendering JS, we have another factor here: Google can’t wait indefinitely to render a page.
Although they already said on Twitter that there is not a pre-defined maximum time, according to several tests we have seen or done, the reference number to be on the safe side is 5 seconds.
This was discovered by chance by Natzir because a client wanted to hide a popup and a language selector modal so Google didn’t consider them intrusive. What he did was loading them after the “document ready” event so they didn’t appear on the DOM, and try with different amounts of seconds to see if Google was seeing them or not. Finally, he observed that with more than 5 seconds, the popup and the modal didn’t appear o the render nor on Google’s cache. But if you want to be sure, it’s better to make those elements load after the user interacts, so Google won’t execute it.
Warning! This a reference number, not a rule! It can vary between websites and also through time (Lino has checked that it can be more than 5 seconds). If you want to make sure Google is able to render and see all your content, besides checking it on the index, the best way is to check how your pages are rendering on the Mobile-Friendly Test Tool, and try to make your website to render as fast as possible.
Google renders JS in 2 phases
In the last Google I/O, Google confirmed what we have been noticing for some time: that JS sites are indexed in 2 phases
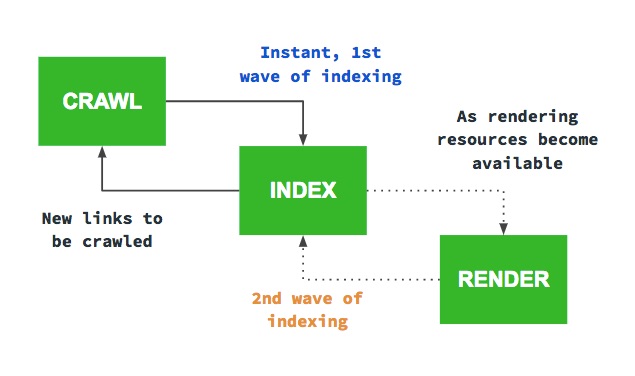
If you a geek like us, you will find curious to know that before Percolator (Natzir talked about it here), Google used MapReduce and Google File System (thanks to those, Hadoop was born). Simplifying a lot, before this new architecture, Google worked in batch, and now it works on the fly. This makes crawled pages to be indexed instantly.
The problem is with JS sites, as Google needs to render them to see the content and the links; if not, Google would be missing a big part of the web. As we have seen before, rendering costs a lot and cannot be done instantly as that would make Google spend way more resources easily. They need to index JS sites in two phases.
So they included a WRS subsystem in Caffeine, based on Chrome 41, which has serious implications that both SEOs and developers must take into account.
Update May 2019: Googlebot will use the latest version of Chromium from now on (74 at the time of this post), allowing it to use +1000 new features. This does not change anything regarding the 2 waves of indexing and the official SEO recommendations if you have a PWA or a site that depends on JS to display content.
One of the things that affect us and that we need to understand is that canonical and rel=amphtml tags, and HTTP status are read and processed only on the first wave (on the initial fetch of the page) and there is no second chance. We didn’t have any idea about the rel=amphtml until John Mueller said it, but it makes sense.
Regarding the canonical tag, it’s a difficult topic. Even if Google said that they only read the tag on the first fetch, and not after rendering the page, there has been cases where they actually did it. The amazing Eoghan Henn setted up a test where he demonstrated that Google was actually reading the canonical tags on the rendered version and applying them
Even if it works sometimes, that doesn’t mean is a good approach to have canonical tags only in the JS rendered version of the page, as serving it on the initial fetch is the only way to guarantee that Google will see the tag.
On the other side, Google said that if noindex, hreflang and rel=next/prev tags are not on the raw HTML, but on the JS rendered version of the page, it’s ok (as they will read the tags after rendering the page).
Same as with the canonical tag, even if Google is able to read and process these tags on the rendered version of the page, we would not recommend to depend on it and the best option is to serve those tags directly on the raw html, to make sure Google is able to read them on the first place. Given that Google delays JS rendering, if that delay is long (some days, for example), we would have pages with noindex, that should not be on the index, but that will be for those days until Google finally renders the page and see that tag.
So, as a good practice, it’s better to always give Google and other bots the meta tags directly on the raw HTML
Other consequence of Google using Chrome 41, is that it cannot render completely websites that use more advanced functionalities not supported by that version of Chrome. If we want to use any of those modern functionalities, we need to make sure that they work on Chrome 41, or find alternatives that do.
Types of events and links that Google follows
Knowing what types of JS events and links Google follows is important as the indexed URLs are the ones taken into account to evaluate the quality of a website.
We know that Google crawls, index and pass PageRank to HTML links (<a href=…) as they confirmed again on the Google I/O:
- <a href=»/this-link»> will be crawled </a>
- <a href=»/this-link» onclick=»cambioPagina(‘este-link’)»> will be crawled </a>
- <a onclick=»changePage(‘this-link’)»> *won’t be crawled </a>
- <span onclick=»changePage(‘this-link’)»> *won’t be crawled </span>
*Not being crawled doesn’t mean that if someone links to that URL it won’t get indexed by Google. Most of the errors of indexed filters come from problems like this.
We also know that Google crawls and index anything that seems like a URL, because they want to discover new URLs, but they won’t pass PageRank (doesn’t mean they won’t appear if you search):
- <a onclick=»changePage(‘/this-link’)»> will be crawled </a>
- <span onclick=»changePage(‘/this-link’)»> will be crawled </span>
- /this-link will be crawled
I believe it was 7 years ago, when in the Webmaster Tools (now Search Console) of a client, a lot of 404s started appearing, at the same time a Google Analytics virtual page implementation was made. Since then, I include anything that appears on the html and looks like a URL on the robots.txt, although the best approach is to modify the code so they don’t look like URLs.
There are also other type of events: onscroll and onmouseover. Onscroll events are executed sometimes, while onmouseover events are not executed
If you have a pagination implemented with onscroll, the first pages can get indexed. One of those things that you discover by chance and that later on Google confirms
Rendering approaches for JS sites
In order to understand the different rendering options for JS sites, the easiest way is to imagine PWA as the IKEA of internet:
- Traditionally, when we (clients) want to buy furniture, we go to a specialised shop (a company), buy the furniture and the company delivers to us the final product, ready to use.
- Later on IKEA appeared, where the client choose the furniture, but instead of receiving the final product, s/he receives different parts and some instructions on how to assemble it, so the client is the one that needs to perform the physical task of assembling the furniture in order to get the final product s/he bought. Besides, sometimes, in order to assemble the product, the client needs to buy extra things from the company (special screws, special tools, etc.). Everything comes on the instructions.
- After some time, IKEA noticed that some clients wanted their products, but didn’t want to assembly the products themselves: they wanted the final product directly. So IKEA launched a new service: you can buy furniture and get someone from IKEA to mount it for you, so you receive the final product.
With this analogy, the client would be our web browser, and IKEA would be the server. Based on that, we have 4 different scenarios when choosing a rendering system:
Client Side Rendering (CSR)
When we talk about pure Client Side Rendering, the client (the web browser), receives an almost blank html on the initial fetch, and the browser is the one that needs to work to “create” the final html based on the resources and JS (instructions) that receives from the server:


This is the option that PWA developers initially used (and in a lot of cases, they continue using), and it is the worst one in terms of SEO, as without executing the JS and rendering the page, there is nothing (no content, no links)
Server Side Rendering (SSR)
Due to the SEO problems with CSR, and the same way IKEA did, JS frameworks started developing new functionalities that solved the problem: without losing the PWA advantages, the server will execute and render the page itself and send the final html to the client:
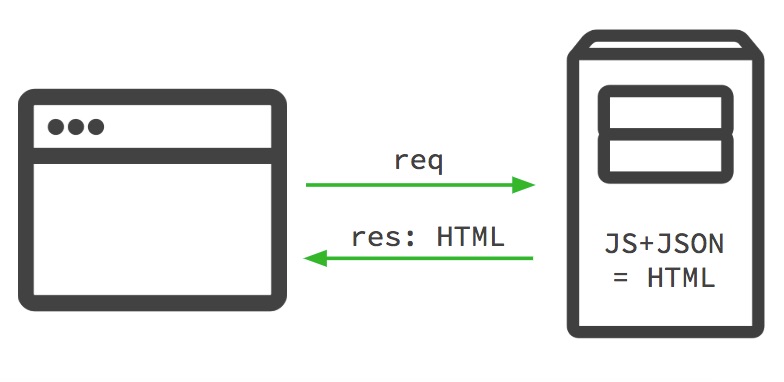

This way, the client (the web browser) receives a final HTML with content and links, without needing to execute and render JavaScript. If JavaScript is enabled, it will then take control of the page and the user can navigate/interact on “PWA mode”. If not, s/he can navigate/interact as in a “normal” webpage, without the PWA advantages
Hybrid Rendering
The third rendering option is a combination of the two previous ones: part of the page is sent pre-rendered from the server, and the rest needs to be rendered on the client.
A really common case of Hybrid Rendering is pre-rendering those parts of the site that all pages on the PWA use (for example, a menu), and leave the specific parts (the main content) to be rendered by the client. In the next example, the “App Shell” (the top area, with blue background) would be sent by the server pre-rendered (SSR), while the area below (the main content) would not appear on the first fetch and would need to be rendered entirely by the client (CSR)


Dynamic Rendering (DR)
This is the option Google recommended officially on Google I/O, and it basically consists on… ¡cloaking!


Yes, you are reading it correctly. What they said is that if we have a PWA that depends on JS and rendering, and want to avoid problems with Googlebot (and other bots), we need to make sure that Googlebot (and other bots) receives a rendered version (SSR) and the rest of user-agents can receive whatever we consider better (CSR, or Hybrid Rendering). This way, Googlebot will be able to see all the content and links without having to render the page. Basically, the content that Google will see it’s the same one the users will see once the page is rendered on their browsers.
A clear example of a big website that is applying this method, and that belongs to Google itself, is Youtube. In the following screenshots (you can try it yourself with this tool) you can see that when visiting a video URL, if the User Agent is Googlebot, the server sends directly the final page with the content and links. If the user agent is a “normal user”, the server sends an empty html, with just the structure and with no content nor links:


SSR better for users, CSR better for servers
What strategy is the best for each case? For users, at least for the first interaction, the best option is SSR:
- Netflix, which is a PWA built with React, and that has invested a lot on working with this technology, saw a 50% performance improvement on their landing pages (those they use to acquire users) by moving from CSR to SSR
- Walmart got to the same conclusion, where now most of their pages work with SSR
Why? It’s simple. Let’s recap how both techniques work:
- With SSR, the server sends the “final” HTML, with all the content and links “ready to see”, without need of rendering on the client (the web browser)
- With CSR, the server sends an empty html, which needs then to be “completed” by the client (the web browser) executing the JS and rendering the page.
This implies that:
- With CSR, the server answers faster (so we can have a better TTFB), while with SSR the server has to use more resources to render and it takes more time to answer
- With SSR, the client (the web browser) receives a “final” HTML, that can be painted faster so the user can see the content faster. With CSR, on the other side, depending on the device of the client, it will take more or less time to render and paint the page.
As you can see on this image with the tests made by Walmart, with SSR the client starts seeing the content sooner, even if the server takes a bit more of time to answer:


So, if CSR is worse for SEO (because we depend on the search engines’ capacity of rendering the page), and SSR is faster for users, why would anyone use CSR? Because of the same reason IKEA sells furniture by pieces: it’s cheaper.
The biggest advantage of CSR is that it’s cheaper for the IT department: as all the rendering and execution of JS happens on the client, the server is less loaded. If we move to SSR, all that work will happen on the server, which can be very expensive as we have already seen.
Google’s official recommendation
As we said before, Google recommends Dynamic Rendering (that is, SSR at least for Googlebot), but they also announced that in some cases they feel capable of fully see and index small pure CSR sites.
They specifically talked about three factors:
- The size of the site (the number of URLs)
- How dynamic the site is (if it publish a lot or few times, if the content of the URLs is static or it changes a lot)
- Compatibility with Chrome 41
Based on that, these would be Google’s recommendations for each case:
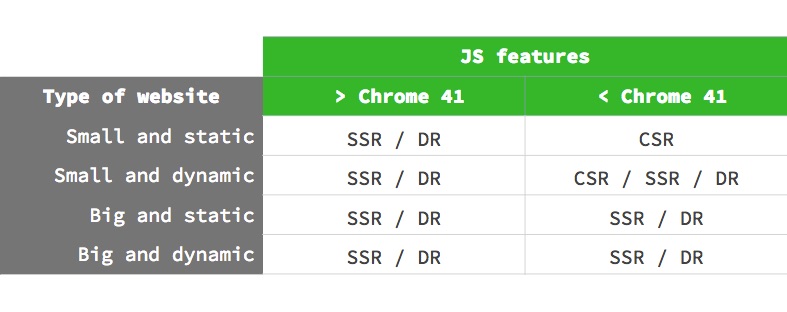

Update May 2019: Googlebot will use the latest version of Chromium from now on (74 at the time of this post), allowing it to use +1000 new features. This does not change anything regarding the 2 waves of indexing and the official SEO recommendations if you have a PWA or a site that depends on JS to display content.
As you can see, the best option is to always use SSR (or Dynamic Rendering) except in smaller, static sites. Even in that case, a certain risk exist also for these sites, so if your project depends on SEO traffic, the best way is to use SSR/DR in all the scenarios.
Here you can clearly see what kind of problems CSR generate, in this tweet by Barry Adams


You can see a graph with the evolution of valid indexed pages in a PWA that was implemented with pure CSR and that eventually changed to SSR. After doing that, the number of indexed pages increased a lot (almost double), reflecting the bottleneck that Google has rendering JS, and the reason they don’t recommend depending on it for big sites.
Good practices for PWA and JS sites
Here we recommend some tools to check if Google has problems rendering our JS site.
PWA and performance audit
You can do this audit using Lighthouse for Chrome and Sonar Whal.
With the Chrome plugin Service Worker Detector, you can easily check the service worker and the manifest on any PWA.
Mobile-Friendly Test
Nowadays, the Mobile-Friendly Test tool from Google is the best way to see how Google renders a page, as it is, in theory, the closest one to what Googlebot actually does. It’s better than the “Fetch and Render” tool on Search Console, as in SC there are more timeouts and the result is not 100% real. The Mobile-Friendly Test is not 100% real also, but it is closer to reality. The problem with the tool is that we cannot scroll down on the page.
Another great feature of the tool is that we can see the final HTML after rendering. and check if there is anything missing, or compare both HTML with tools like Diff Checker. We can also check JS errors blocked assets.
Fetch and Render
This tool from Google Search Console is also really useful, as we can compare how a user and Googlebot willl see our page, and if there is any difference.
We can also use this for any page of any domain, even if it is not ours. For example, you can see how Natzir is able to use the tool for a page from Trivago, thanks to the code shared by Screaming Frog (don’t forget to modify it as explained on the slides)
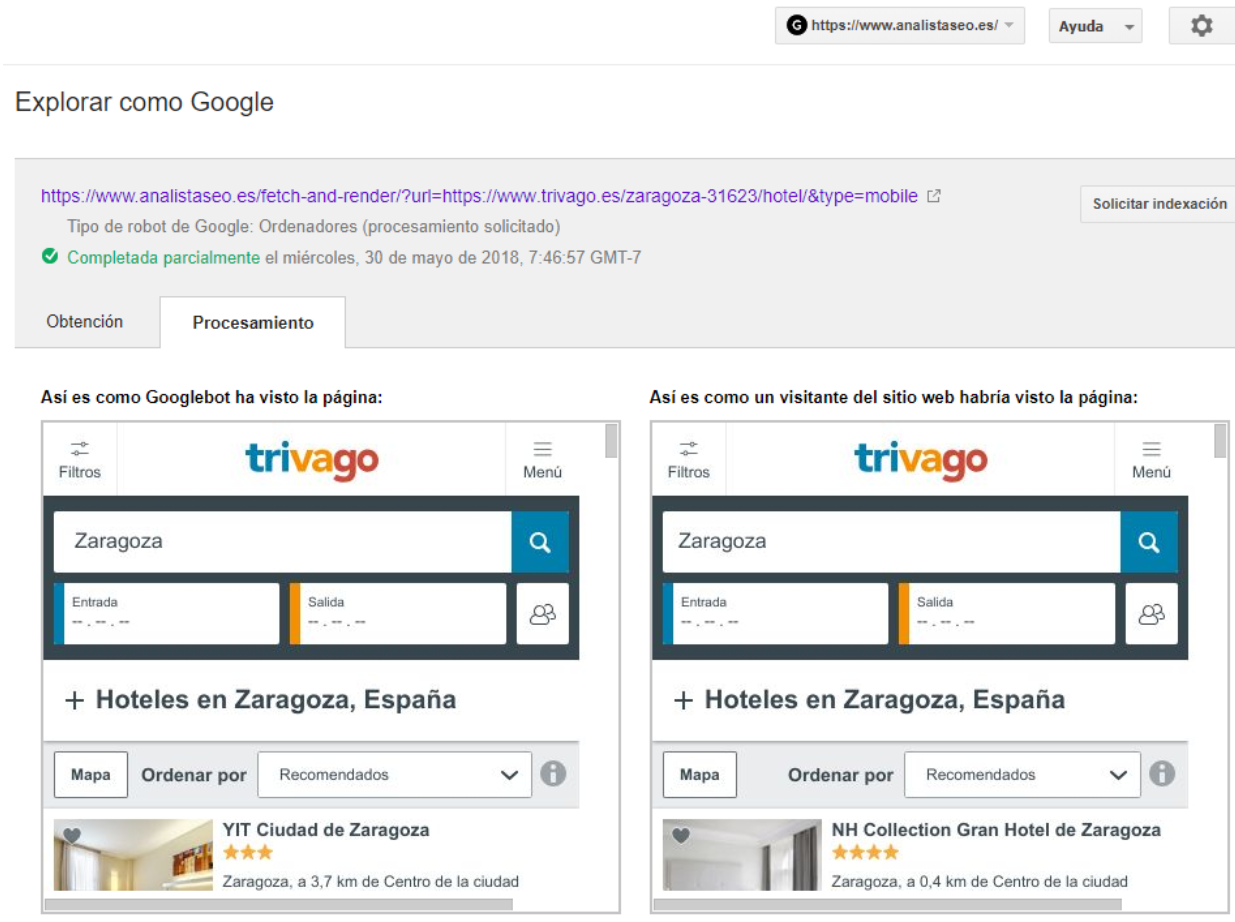

What this code does is to load any page on your domain through an iframe.
You can also use this functionality for staging sites. To do this, you need to add a noindex to all the URLs and only let Googlebot access them using Reverse DNS.
There are other tools you can use, like ScreamingFrog SEO Spider or this online tool developed by Merkle SEO. Thanks to these tools you can modify the amount of time to wait for the rendering and the User Agents. You should aim for getting the page rendered in less than 5 seconds.
Crawl and compare staging with production enviroments
If you are migrating your current site to a PWA using technologies like Angular or React, you can use crawlers like FandangoSEO to crawl your site on staging and also in production, and compare them. Most of the problems on migrations to a PWA happen because of layout changes and not just because of using JavaScript.
As in any migration, you need to check internal linking is the same in staging and production, maintaining the same levels of depth, as well as keeping the same content in both versions. This is a priority on any migration, even more than having redirects with 2 or more hops. It’s also a bad practice to migrate layout, CMS and URLs all at the same time; even if we maintain the links and the redirects are perfect, those are lots of changes at the same time and the site can suffer for 6 to 12 months until Google is able to reprocess and understand everything.
So if you migrate your site to a PWA, test it thoroughly on staging before going live, and minimize the amount of changes
Crawl emulating mobile and rendering JS
With the change to “mobile first indexing” from Google, we also need to check how Google sees our sites as a mobile user and revise the points commented before. With FandangoSEO we can also do this and compare the crawls to see if mobile and desktop are equal or not in terms of internal linking, title tags, etc.
Although you can do this with crawlers, when you just want to check some specific pages you can use these plugins: meta seo inspector and user-agent switcher. In the last one, you can add User Agents for Googlebot, Googlebot Mobile and the ones from Facebook and Twitter (to check open graph and twitter cards data)
- Googlebot: User-Agent String: Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
- Googlebot Mobile: Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2272.96 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
- Facebook: facebookexternalhit/1.1 (+http://www.facebook.com/externalhit_uatext.php)
- Twitterbot: Twitterbot/1.0
You can also use the new Rich Results Test from Google to validate schema.org, which will also show you the rendered HTML. The backside is that it doesn’t allow as much types as the previous one
Browse without JS emulating other User Agents
When you want to check the same as in the previous point but also without executing Javascript, you can use the Web Developer plugin, where you can deactivate JS.
Check console errors and links on Chrome 41
It is a must to use Chrome 41 yourself and check if your PWA works there. You can check Javascript errors, API errors or CSS errors that you will see on the browser’s console. You will see that some of those errors do not appear on the latest versions of Chrome, so if they happen on Chrome 41, they will happen also on Google when trying to render your page.
Another thing to check on Chrome 41 is if the links and menus are accessible, as sometimes, because of unsupported features, they might not work. You can check here which features are supported and which ones are not
There are rumours saying that Google will update its WRS with a more modern version of Chrome in less than a year, but there is no confirmed date. So up to date, Chrome 41 is our reference.
To end with the good practices, here you have some checklist with things to take into account if you use pure CSR or SSR/DR
PWA SEO Checklist for CSR
- Canonicals + metadata do not depend on CSR
- Page renders in less than 5 seconds
- Page loads and is functional with Chrome 41
- Rendered links are <a> elements with their real href
- HTML+design is the expected on Mobile Friendly Tool
- HTML+design is the expected on Fetch and Render with Search Console
- Pages appear on Google after searching for specific text strings
- Content is not replicated in different pages
- Fragments (!#) are not used and every page has its own URL
PWA SEO Checklist for Dynamic Rendering/SSR
- SSR is served to Googlebot and other specific bots (FB, TW…)
- Content Googlebot receives is the same a normal user sees
- Http response codes are the same in both cases
- Meta tags are the same in both cases
- Server is able to manage the rendering under high pressure
- SSR version includes all the content and links in a correct way
- All pages have the expected behaviour in both cases
- Fragments (!#)are not used and every page has its own URL
Apart from that, this checklist from google for PWAs regarding PWA and WPO is also really useful:
PWA Checklist UX & WPO
- Site is served over HTTPS
- Pages are responsive on tablets & mobile devices
- All app URLs load while offline
- Metadata provided for Add to Home screen
- First load very fast even on 3G
- Page transitions don’t feel like they block on the network
- Site uses cache-first networking
- Site appropriately informs the user when they’re offline
- Content doesn’t jump as the page loads
- Pressing back from a detail page retains scroll position on the previous list page
- When tapped, inputs aren’t obscured by the on screen keyboard
- Content is easily shareable from standalone or full screen mode
- Any app install prompts are not used excessively
Experiment: PWA without prerender (CSR)
In order to try ourselves how Google deals with Javascript, we have sacrificed our blogs migrating them from a “normal” WordPress to a PWA that works only when having JS (CSR)
We did this using Worona (now Frontity), which is a platform that allows you to convert a WordPress site into a PWA for mobile users. In our case, we collaborated with them in order to make the PWA available in both mobile and desktop, and that when JS is not enabled, a blank page appears.
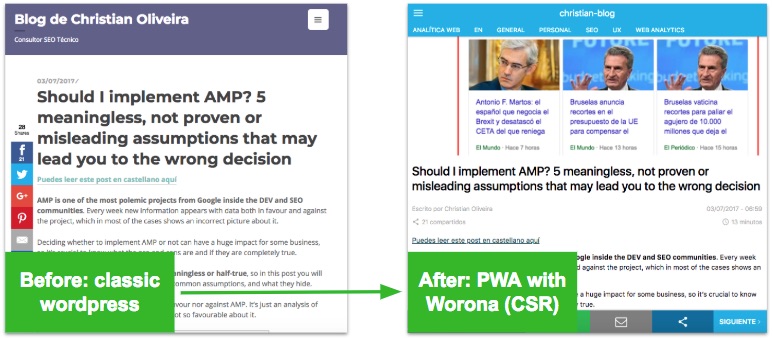

As you can see, if we deactivate JS, all the pages in this blog load only what you see in this screenshot: a blank page without the real content and links to crawl and index:


Once the PWA was enabled on production, we have done different tests.
Disclaimer: as you will see, these tests have been made on a small site, in a small period time and on small scale. We cannot guarantee that the results will be the same in other situations.
Test 1: rendering
The first test was to check if Google was, in fact, able to render and index the URLs from the blog, now that they only work with JavaScript.
In order to do that, we checked first on the Mobile-Friendly Test Tool and on the Fetch and Render Tool on Search Console, where we confirmed that Google was able to render the content.
We used the “Request indexing” option on Search Console to force Google to update the URL on their index, and in less than 15 minutes we were able to check what they did:

Observations:
- Google has been able to render and index the content
- The process has been relatively fast (15’)
Test 2: rankings
Once we validate that Google is able to render the blog and see our content, the next obvious question is if we are going to keep the rankings for that post. In order to check that, we choose a keyword for which the post has been ranking 1 or 2 for 6 months (so it’s a “stable” keyword)


And we check that, once their index has been updated for that URL, we keep the same ranking:
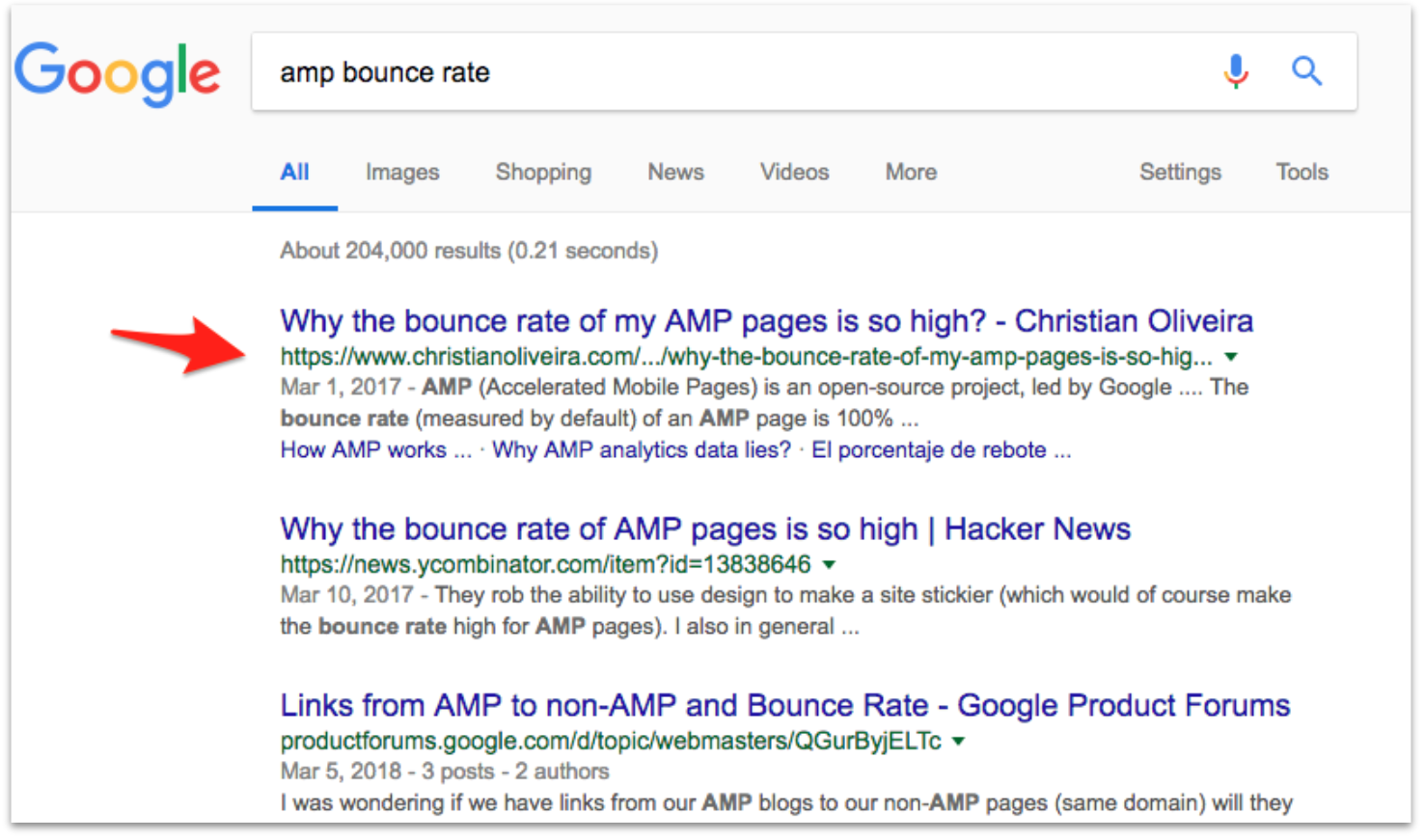

Besides, we also do a search combining the keyword with a piece of text that appears only on the PWA after rendering, to make sure Google is indeed ranking the page taking into account the content that loads after rendering it:


Observations:
- Rankings haven’t been lost after migrating to a PWA without SSR
Test 3: new content indexing
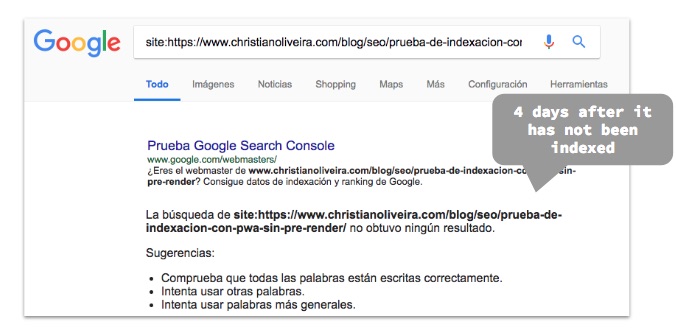
We also wanted to test how much time Google takes on finding, crawling and indexing a new post, so we publish a new one:


As we don’t want to force Google to crawl the new URL, what we do is a Fetch and Render of the blog homepage, and click on “Request Indexing”, where Google will find a link to this new post, to see if they index it and how much time it takes.
Even though we saw a visit from Googlebot to the new URL on the server logs, the page didn’t appeared on Google’s index until 5 days after publishing:

A small mistake when doing this test was that the post didn’t have a lot of content, and the plugin we used (Worona), loads the next post when you scroll to the end of the current post, so when Google was rendering it, was seeing also the content of the next post below:
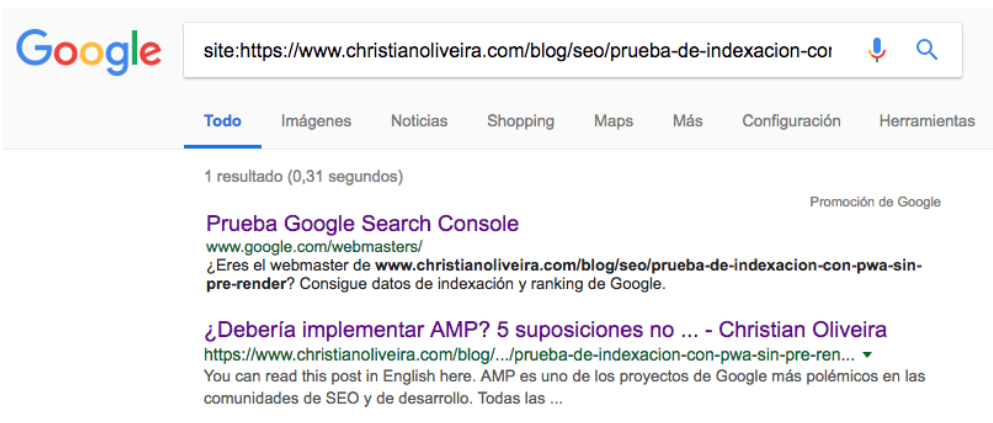

So we will repeat this test.
Observations:
- If we don’t force the indexing, Google takes some time to index new content
Test 4: the two waves of indexing
Last, we wanted to try to see “live” the 2 waves indexing system that Google has confirmed. Same as in the previous case, because we did the test with a URL with not a lot of content, Google ended up loading the next post and indexing that content for this URL
This is what we did:
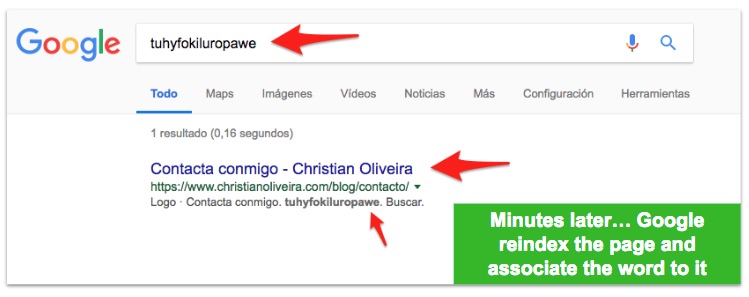
- In a page Google didn’t recrawl yet, we did a change to include a made up word only on the initial html version of the page, that disappears after loading the PWA
- We forced Google to Fetch (not Render) that page on Search Console, and we “Request Indexing”
- Minutes later, when we searched for the word Google was already showing the URL:

- On the other side, when we checked Google’s cache for this page, we found that even though Google indexed the new content, the cache was still showing the old version (the one without PWA that we had before):


- Also, when searching for specific text strings that appeared only on the old version of the page (before PWA), the page was still appearing:
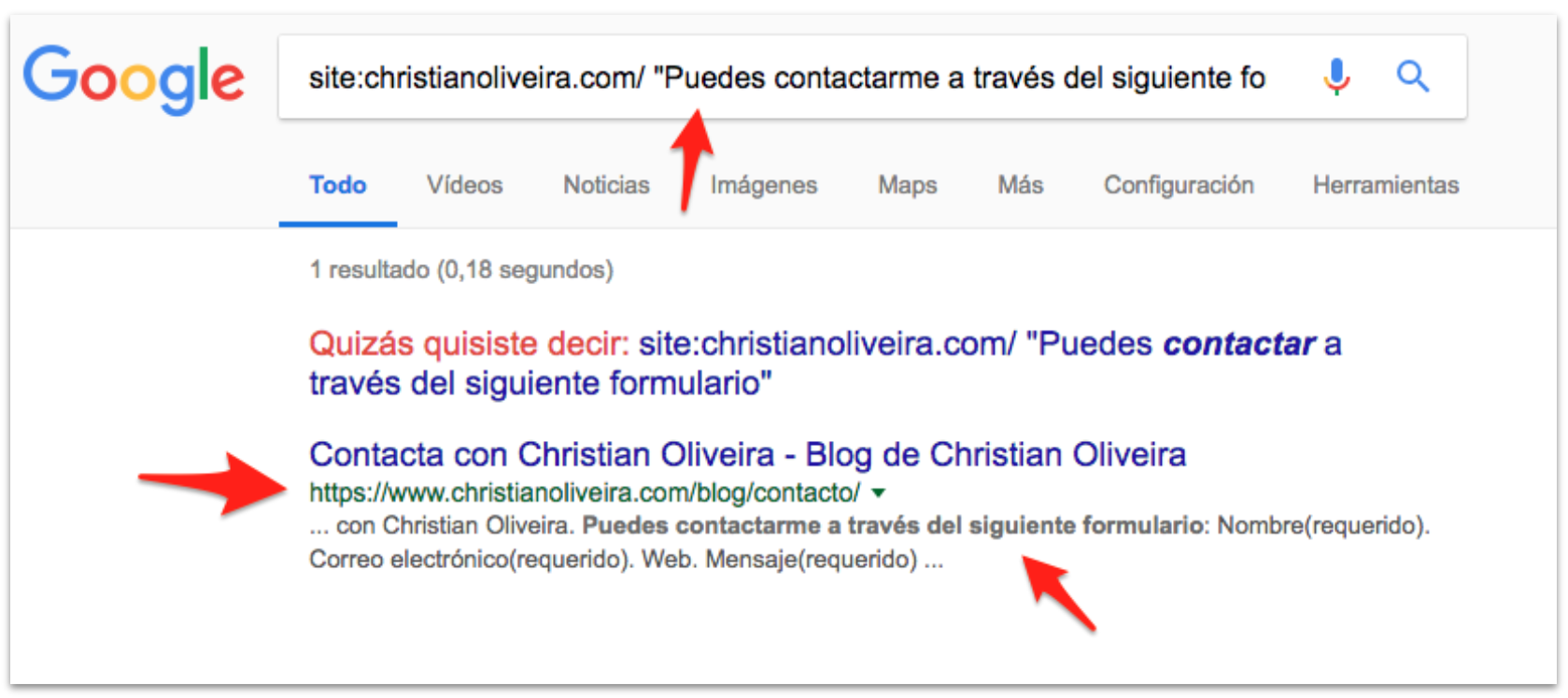

- Days later, Google started showing the PWA version on the cache:
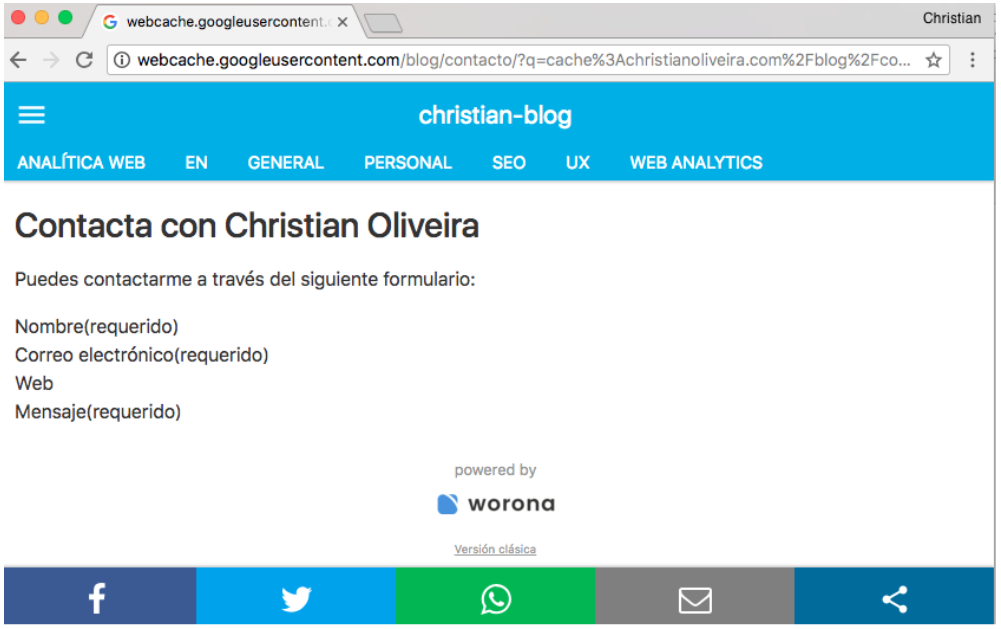

- And from that moment, the page no longer appears for the made up word that is only visible on the initial HTML before rendering:


- Although when checking the «Text-only» version Google’s cache, the word appears:


Observations:
- Before rendering the page Google has indexed the content on the page without JS (first wave)
- This new content has been associated to the previous version of the web (the one without PWA)
- Once rendered, the page only ranks for the content present on the rendered version (second wave indexing)
Conclusions
- Up to date very few websites have migrated directly to a CSR PWA (no pre-rendering) for all user-agents. Those who did and lost traffic, had also other technical problems (e.g. hulu.com)
- New websites which are created directly as CSR PWA can rank, but they have problems with indexing
- Up to date, and regarding Google, Dynamic Rendering is the solution that works without any problems
